 By David Bianco May 17, 2023
By David Bianco May 17, 2023
In the complex world of Internet security, TLS encryption reigns. The powers behind the throne are the Certificate Authorities (CAs) that play a crucial role in verifying websites' identities and regulating the trust we place in those sites. However, understanding the trustworthiness of the CAs themselves can be challenging. In this blog post, we dive into our recent research project, in which the Splunk SURGe team analyzed more than five billion TLS certificates to find out if the CAs we rely on are really worthy of our trust. Because quis custodiet ipsos custodes?
Project Background
I’ve been with SURGe for about a year now, and when I was considering joining, the thing that I was most excited about was the opportunity to do cybersecurity research not necessarily tied to Splunk or its products, but working for the common good. Plus, I’ll be honest, I was eager to get that unlimited Splunk license!
After I had a few weeks to settle in and meet the team, I had to finally get down to the serious business of figuring out my first project. I knew I wanted something with a lot of data, something with practical applications, and something that, ideally, no one else had done before. I had done some work with Certificate Transparency at my previous company, and I always thought it was kinda neat to have access to all the website certificates used across the Internet, so I started thinking about what I could do with all that data.
The Big Question
When you think of TLS and website certificates, you think of the Certificate Authorities that essentially vouch for the authenticity and, by extension, the legitimacy of the sites for which they issue those certificates. Our whole concept of Internet security relies on us trusting both the root and the issuing CAs (as well as the intermediate CAs if there are any). If we can’t actually trust the CAs, the whole scheme falls apart. All the major operating systems and web browsers ship with a list of pre-configured root CAs that they trust on our behalf, based mostly on their review of the CAs’ policies and procedures. In my literature review, I was only able to find one other source that had done anything similar, but even they weren’t looking at all the certificates.
| Browser/Platform | # of Trusted Roots |
|---|---|
| Chrome | 138 |
| Firefox | 140 |
| Safari / MacOS | 154 |
Table 1: Number of Trusted Roots per Browser (Source: Author’s Computer)
So I decided to give it a shot!
The Research Team
The first item on my agenda was to assemble a small research team to help me collect and analyze all this data. Mikael Bjerkeland was our Splunk architect and administrator. He designed, built, and maintained our entire data infrastructure, as well as getting all the data ingested into Splunk. Kelcie Bourne (a fellow SURGe member) and Philipp Drieger both stepped in to help out with the data analysis. Big thanks to them and to the rest of the SURGe team for their support during the entire project!
Methodology
Our team’s research plan was fairly straightforward:
- Download all the certificates used for secure websites on the Internet (easy, right?).
- Cross-reference the certificates with intel data on domains and websites confirmed to have been used for malicious activities.
- Do some math to determine which CAs were responsible for more than (or less than!) their share of certificates that ended up being used for malicious purposes.
Of course, as with most things in the real world, it’s never quite this easy. We’ll talk about some of the challenges we faced and how we adapted our initial methodology shortly.
What is Certificate Transparency Anyway?
Certificate Transparency (CT) is a security measure designed to improve the trustworthiness of the Public Key Infrastructure (PKI) that underpins secure internet communication using TLS certificates. The PKI relies on CAs to issue, validate, and revoke digital certificates for secure websites. However, the system's trustworthiness can be compromised if a CA mistakenly issues a certificate to a malicious actor or if a CA itself is compromised. CT addresses this issue by providing a publicly accessible, verifiable, and auditable log of issued certificates, allowing for increased transparency and accountability.
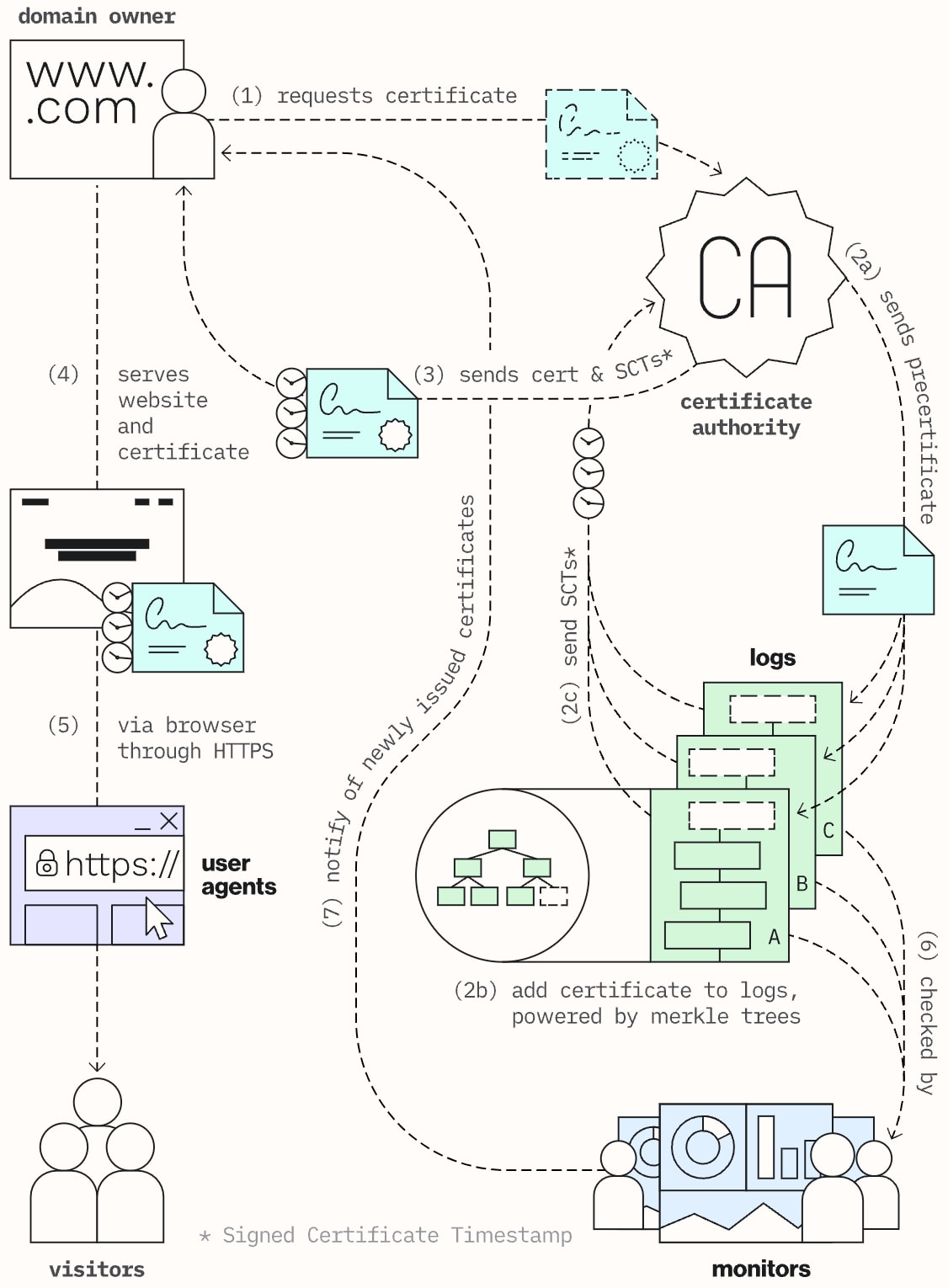
Figure 1: The CT Ecosystem (Source)
Certificate Transparency Logs (CTLs) are the backbone of the CT system, functioning as append-only databases that store publicly trusted certificates issued by the CAs. These logs are cryptographically protected from tampering, so once a certificate is added to a CTL, the record of it is immutable.
CT is crucial in today's digital landscape, as it significantly reduces the risk of illegitimate websites successfully masquerading as genuine entities through fraudulently obtained certificates. In addition, by improving the transparency and accountability of the PKI, CT bolsters the overall trust and security of the internet for users and organizations alike.
Data Collection: Certificates
CTLs have a notable feature - a standard, public API that allows users to access stored certificates. When validating certificates, most browsers refer to CTLs. Since 2018, Chrome has mandated Certificate Transparency for all certs. As Chrome and its related browsers are widely used, web operators require their sites to be compatible with them. Therefore, CTLs hold virtually all certificates for secure websites on the public Internet.
The CTL API was particularly useful for us since we needed a straightforward method to download all these certs. Rather than spidering the web and connecting to every secure site, we used the CTL API, which made the process much simpler.
In the end, we downloaded the full contents of 15 different transparency logs, the ones Chrome uses to validate certificates. This resulted in about five billion unique certificates, all of which we ingested into our project’s Splunk instance. In total, we found 479 root CAs and about 78,000 issuing CAs in our dataset.
Data Collection: Intel
In addition to the certificates themselves, we needed to find out which ones had been used for malicious purposes. To do this, we collected information about malicious domains and websites from multiple threat intelligence providers. By combining data from multiple intel providers, we ensured that our analysis was based on a comprehensive and diverse set of threat information. We intentionally looked for sources spread across the globe to help counter any geographic bias.
We collected intel data from seven different sources, including commercial intel providers DomainTools and Group-IB, public or semi-public sources such as the JPCERT/CC’s list of phishing sites and FIRST.org’s members-only intel-sharing platform, and a number of databases provided by private security teams, like the Yahoo! Paranoids.
We ended up with 185,000,000 observations of confirmed malicious activity, which we were then able to match against the certificate subjects and alternate names in our dataset.
Analysis Challenges
We encountered several challenges during our analysis, the most obvious of which was the sheer volume of the data involved. We were dealing with billions of records, which is no small feat. The enormity of this dataset required us to invest significant computational resources and efficient data handling strategies to process, analyze, and extract meaningful insights.
Just getting access to the certificates was a challenge of its own, partly due to the size of the CTLs and partly due to the complexities of the x509 certificate format. To tackle these problems, we developed a custom download and parsing solution. This tool was specifically designed to navigate the public CTL API, retrieve the stored certificates, and parse the data into a format suitable for further analysis. We did find a few existing tools for doing this, such as CaliDog’s Axeman, but we ended up having to write our own parallel download tool in order to fetch the data in a reasonable amount of time, especially since we were dealing with multiple CTLs.
Another challenge we faced during the analysis was matching intel data to certificate subjects. It's not as straightforward as you might think since the certificates often contain inconsistencies or variations in how information is represented. For example, in many cases, the certificate subject or alternate name might be something like *.evil.com, while the intel observation might be on a specific host in that domain, such as really.evil.com. Or vice versa. This made it tricky to establish clear matches between intel and certificates in some cases. Also, many certificates made use of the Subject Alternative Name (SAN) extension, which allows the certificate to be used for more than one website or domain, effectively increasing the number of certificate subjects we needed to match against intel data far beyond five billion.
Making Unfair Comparisons Fair
The most vexing problem we encountered was the extreme variation in the population sizes of Certificate Authorities (CAs), which complicated comparisons between them. At first, we just treated all the roots and issuers the same and tried to make direct comparisons between all roots and then all issuers, but it turned out not to be quite so simple; some CAs are just SO MUCH LARGER than others that you couldn’t always compare them. After all, our largest root CA, ISRG Root X1, the main root used by Let’s Encrypt, was responsible for 860,000,000 certificates. You can’t directly compare that to a CA that issued “only” 10,000 certificates.
Instead, we split the roots and the issuers into different tiers according to how many certificates each CA was responsible for. We defined Tier 1 CAs as either the roots or the issuers with the largest number of certificates. Both populations had a very long tail of CAs with only a few certificates in our dataset, so we chopped off that tail and called those Tier 4. Tiers 2 and 3 fell somewhere in between. What we were left with were tiers where all the CAs were roughly equal in size so that we could make fair comparisons.
| Root CA Tier | Certificate Population | CAs in Tier |
|---|---|---|
| Tier 1 | > 10M | 13 |
| Tier 2 | 1M - 10M | 9 |
| Tier 3 | 100K - 1M | 11 |
| Tier 4 | < 100K | 464 |
Table 2: Root CA Tiers
| Issuing CA Tier | Certificate Population | CAs in Tier |
|---|---|---|
| Tier 1 | > 100K | 9,631 |
| Tier 2 | 10K - 100K | 187 |
| Tier 3 | 1K - 10K | 10,001 |
| Tier 4 | < 1K | ~58,000 |
Table 3: Issuing CA Tiers
How We Evaluated and Ranked the CAs
To assess the trustworthiness of the CAs, we first categorized them into comparable tiers. Then, we tallied the total number of certificates each CA issued or anchored as the root of the trust chain. We also cross-checked the certificate subjects and SANs against our intel data to determine how many times each CA's certificates were associated with malicious activities. We made sure that we never counted the same certificate more than once even if it had multiple matching names. Based on these two counts, we calculated the percentage of certificates used for nefarious purposes by each CA.
Ordering CAs by this percentage would be straightforward, but didn’t help us figure out which CAs are issuing more or less than their share of certificates used for said nefarious activities. What we wanted instead was not just an ordered list of percentages but an easy way to find the “risky” and “trusty” outliers of those percentage values. That’s where the z-score comes in.
Put simply, a z-score is the number of standard deviations an individual data point is above or below the mean of all the data points. Z-scores are often used as simple outlier measurements, with a threshold above which one would consider the value to be an outlier. We chose a common but conservative threshold of 3. That is, any z-score >= 3 would be considered a “risky” outlier, while any z-score <= -3 would be considered a “trusty” outlier.
Key Findings
Ordering the CAs in each tier by their z-scores allows us to extract some useful insights from the certificate data. But before we get into the insights themselves, it's crucial to understand that being an outlier does not automatically mean the CA is doing anything wrong; instead, these CAs require closer examination and individual risk assessments to accurately gauge their trustworthiness.
Let’s look at the root and issuing CAs, tier-by-tier.
Root CAs
Tier 1: This top tier is composed of 13 root CAs, all of which are well-known industry giants. We found no outliers in this category, either risky or trusty, which aligns with expectations given their market dominance and fierce competition that encourages all CAs to maintain high levels of trustworthiness.
Tier 2: The second tier comprises nine root CAs, which are still large players but not quite as dominant as those in Tier 1. As in the previous tier, we observed no outliers, indicating that these CAs also prioritize maintaining consistent trustworthiness to stay competitive in the market.
Tier 3: This tier includes 11 root CAs, which are somewhat smaller than those in the previous tiers. Nonetheless, we found no outliers among them, suggesting that these CAs are also diligent in maintaining a consistent level of trustworthiness.
Tier 4: The fourth tier is where things start to get interesting. It contains 464 root CAs. Again, we found no trusty outliers. Ignoring one CA, Internet Security Research Group (a root for Let’s Encrypt), because it only had two certificates in the dataset, we were left with four risky outliers: eMudhra Technologies, Google Trust Services, E-Tugra Certification Authority, and SSL.com. Of these, Google Trust Services is probably the most surprising, but according to Google’s PKI documentation, the GTS Root R1 certificate is used not only for Google’s own services but also individuals hosting content on Google servers, which may account for their high outlier score.
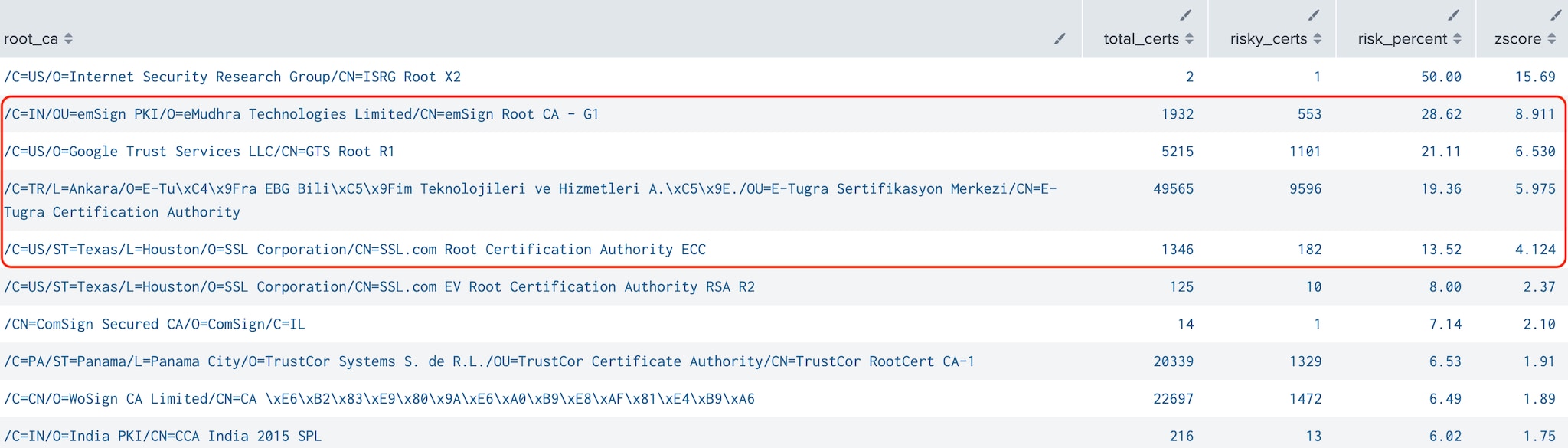
Figure 2: Riskiest Roots (Tier 4)
Issuing CAs
In contrast to the root CAs, in which we found outliers only in the lowest tier, we found risky outliers in all issuer tiers. However, as with the root CAs, we found no trusty outliers in any of the tiers.
Tier 1: In this tier, we discovered two risky outliers: GoDaddy and ZeroSSL. The high ranking of GoDaddy could be attributed to its popularity as one of the leading web hosting providers, whereas ZeroSSL's free tier might inadvertently attract malicious actors.
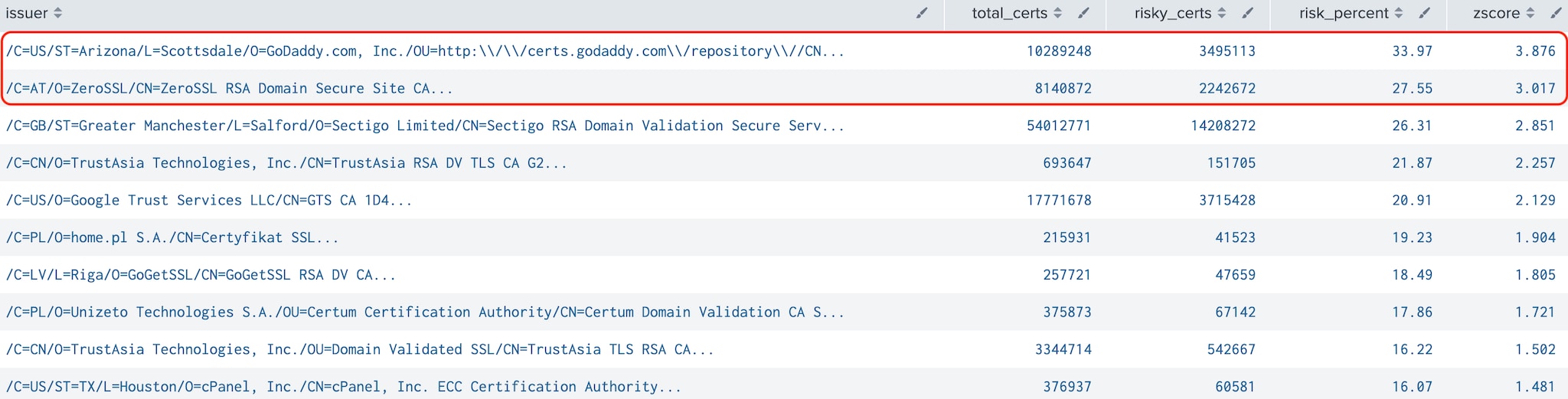
Figure 3: Riskiest Issuers (Tier 1)
Tier 2: This tier had one notable outlier, TrustOcean Encryption365, a Chinese company with an unclear current status (we were unable to load their website during our research, and their GitHub repo has not been updated in quite some time). This finding highlights the need for further investigation to understand the risks associated with this CA.
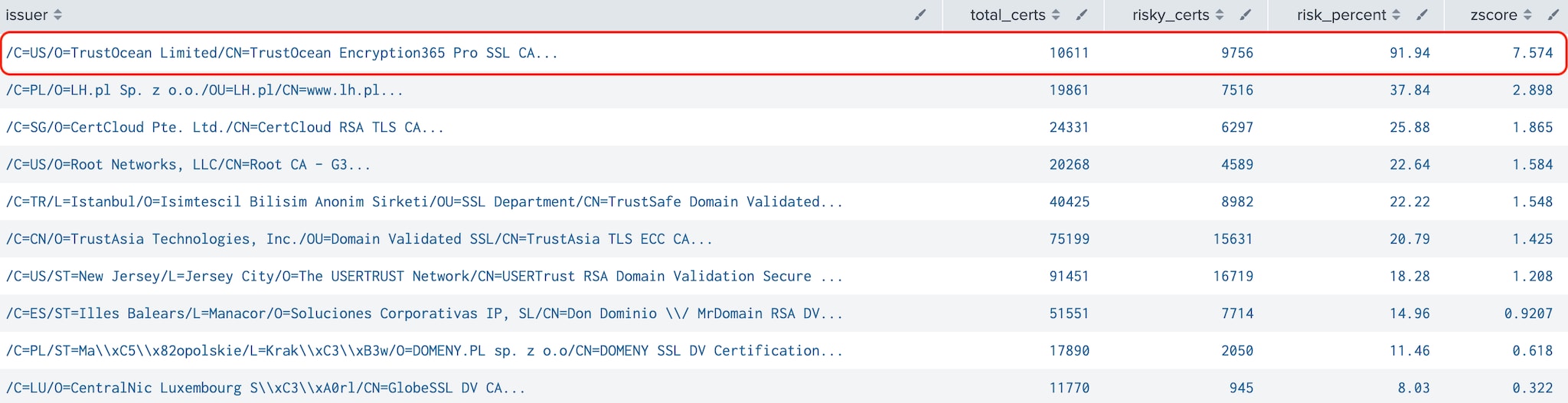
Figure 4: Riskiest Issuers (Tier 2)
Tier 3: Several risky outliers were identified in this tier, including two eMudhra Technologies issuers (which explains why they showed up as a root outlier) and RapidSSL, one of several CAs operated by Digicert, a well-established CA. This observation underscores the importance of continuous monitoring, even for reputable CAs.
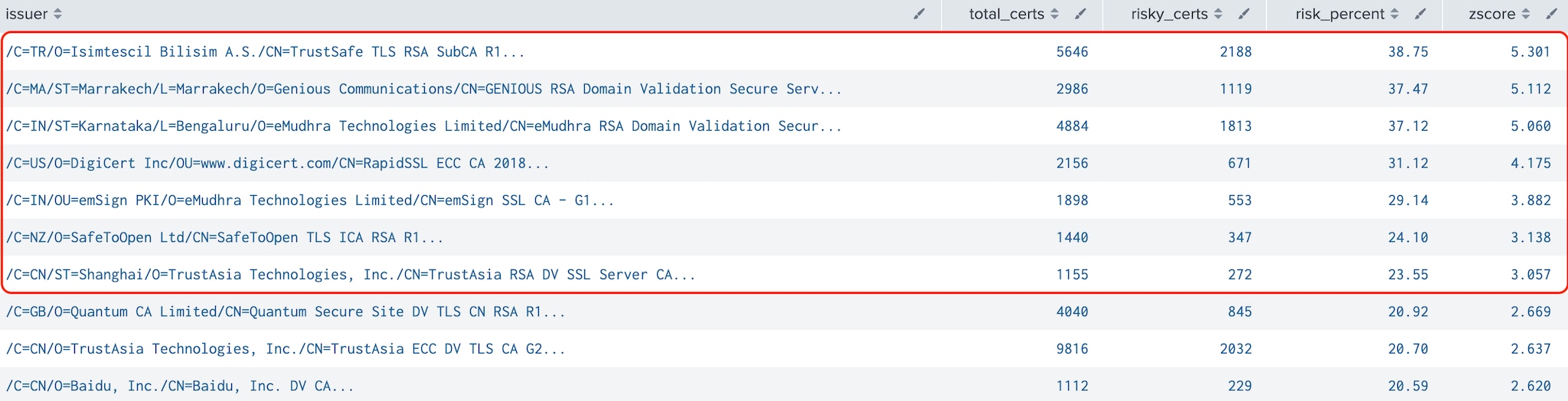
Figure 5: Riskiest Issuers (Tier 3)
Tier 4: We found no valid results in this tier, as all CAs had too few certificates. Due to the noise created by having so many tiny issuers, we opted to ignore this tier entirely.
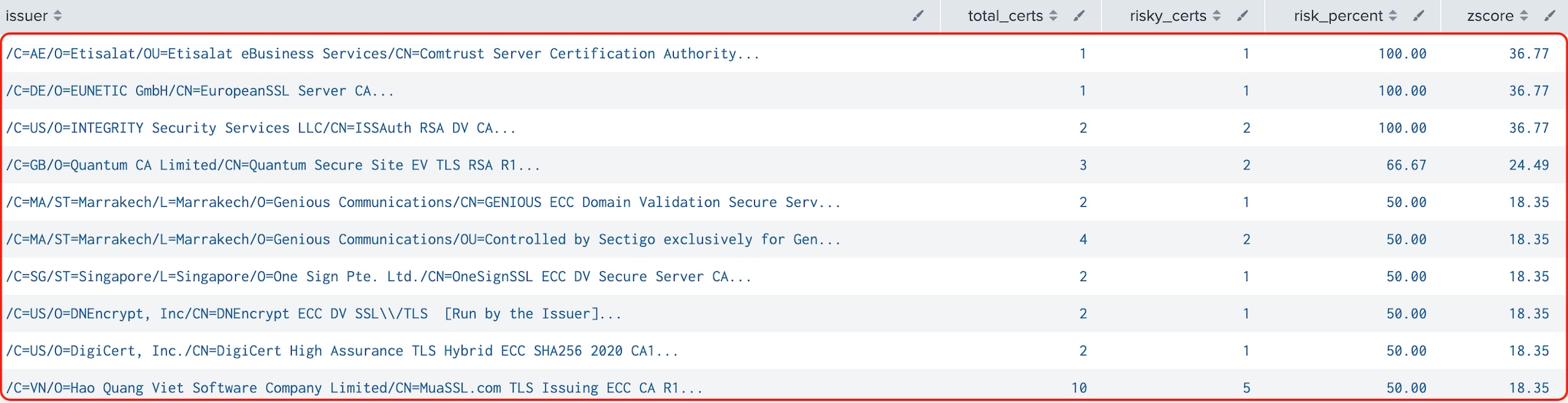
Figure 6: Riskiest Issuers (Tier 4)
Conclusions and Recommendations
To sum all this up, we found a total of 14 risky outlier CAs: four roots and ten issuers. But the question really is “so what?”
Most organizations don’t need to rush out and start blocking the risky roots, because they’re all Tier 4. You’re not that likely to encounter many of their certificates, so the reward for the effort is very low. Blocking certain well-chosen issuers might be a different story, but you probably can’t. We are unaware of any tools that allow the blocking of certificates from specific issuers, especially across an entire organization.
However, that’s not to say there’s nothing you can do with this data. For example, one useful application could be utilizing the risk rankings as inputs for Risk-Based Alerting (RBA). Another might be to use them for threat hunting data enrichment. Both of these would require certificate logging, including details about the roots and issuers, but there are tools for this. However, this would also require regular updates to risk rankings to ensure they stay up-to-date, which threat intel vendors do not currently provide.
Still, if you’d like to try RBA or hunting with our rankings, check out the project’s GitHub repo where you can download the risk rankings for all the roots and the top 10,000 issuers and give this a try yourself. You can also watch the RSAC 2023 speaking session to learn more about this research.
As always, security at Splunk is a family business. Credit to authors and collaborators: David Bianco, Mikael Bjerkeland, Philipp Drieger, and Ryan Kovar.