 By Stephen Watts October 30, 2023
By Stephen Watts October 30, 2023
Predictive modeling is the process of using known results to create a statistical model that can be used for predictive analysis, or to forecast future behaviors. It’s a tool within predictive analytics, a field of data mining that tries to answer the question: “What is likely to happen next?”
Digitization has created enormous volumes of real-time data in virtually every industry. This data can be used to analyze historical events to help forecast future ones, such as financial risks, mechanical breakdowns, customer behavior and other outcomes. However, the data produced by digital products is often unstructured — (i.e., not organized in a predefined manner) — making it too complex for human analysis. Instead, companies use predictive modeling tools that employ machine learning algorithms to parse and identify patterns in the data that can suggest what events are likely to happen in the future.
This “crystal ball” capability has applications across the enterprise; businesses use predictive modeling to make their operations more efficient, get their products to market more quickly and improve their relationships with their customers, to name just a few. It is an especially powerful tool in ITOps and software development, where it can help predict system failures, application outages and other issues.
Below, we’ll look at how predictive models work, the various predictive modeling techniques, the benefits of predictive analytics, and how to choose the right predictive model for your organization.

Predictive Modeling Basics
What is predictive analytics? Predictive analytics refers to the application of mathematical models to large amounts of data with the aim of identifying past behavior patterns and predicting future outcomes. The practice combines data collection, data mining, machine learning and statistical algorithms to provide the “predictive” element.
Predictive analytics is just one practice within a spectrum of analytics approaches that include the following:
- Descriptive: As the most basic type of analytics, descriptive analytics identifies a problem or answers the question, “What happened?” However, it can’t tell you why something happened, so it’s usually used in tandem with one or more of the other types.
- Diagnostic: Diagnostic analytics picks up where descriptive analytics leaves off and makes correlations that explain why something happened.
- Predictive: Predictive analytics takes historical data and identifies patterns that point to likely future events.
- Prescriptive: As the most sophisticated type, prescriptive analytics suggests what course of action to take to solve or prevent a problem.
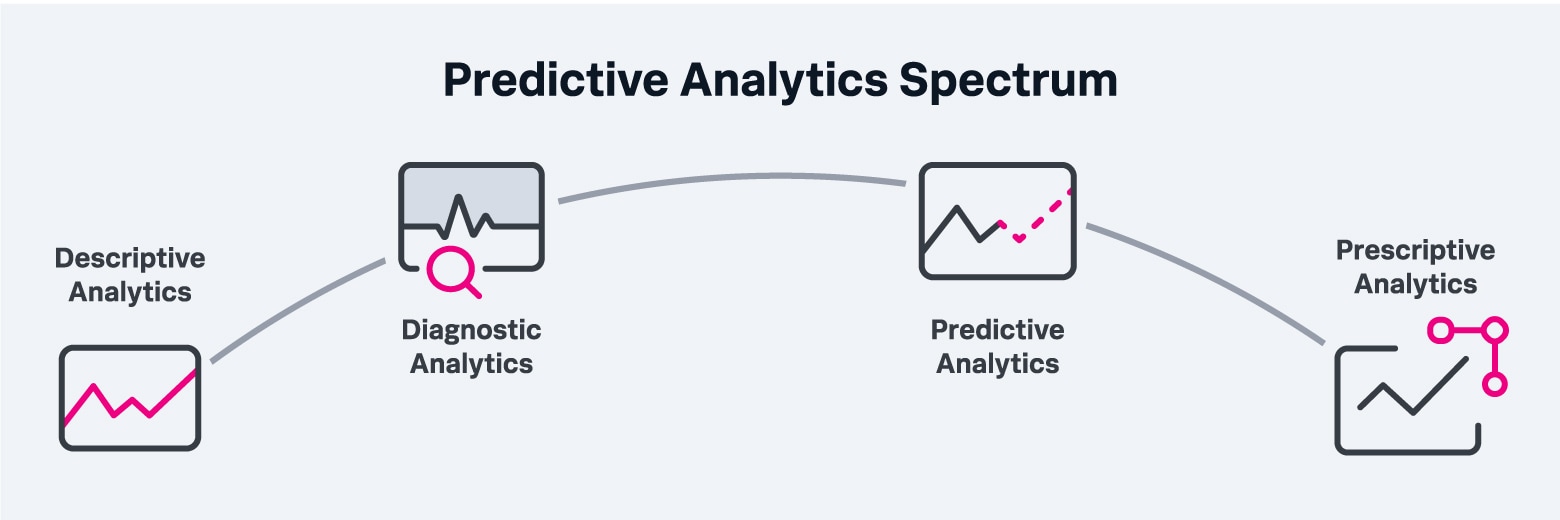
Descriptive and diagnostic analytics tools are invaluable for helping data scientists make fact-based decisions about current events, but they’re not enough on their own. Businesses must be able to anticipate trends, problems and other events in order to be competitive. Predictive analytics builds on descriptive and diagnostic analytics by identifying patterns in data outputs and forecasting possible outcomes and the likelihood that they will happen. That allows businesses to plan more accurately, avoid or mitigate risk, quickly evaluate options and generally make more confident business decisions.
Predictive analytics can help retail businesses predict customer long-term value, allow healthcare practitioners to determine the most effective course of patient treatment and let educators identify students who need more personalized attention, to cite just a few use cases.
Predictive analytics has been particularly transformative in IT. The increased complexity of architecture sourced to virtualization, the cloud, the Internet of Things (IoT) and other technological advances exponentially increases the volume of comprehensible data, resulting in long delays in issue diagnosis and resolution. Powered by big data and artificial intelligence (AI), predictive analytics overcomes these difficulties. As it identifies patterns, it can create predictors around performance issues, network outages, capacity shortfalls, security breaches and a host of other infrastructure problems, resulting in improved performance, reduced downtime and an overall more resilient infrastructure..
How Predictive Analytics Models Work
Predictive analytics models work by running machine learning algorithms on business-relevant data sets. Building a predictive model is a step-by-step process that starts with defining a clear business objective. This objective is often defined as a question and helps determine the scope of the project and the appropriate type of prediction model to use. From there, you’ll follow a series of steps as outlined below.
- Prepare your historical data for statistical analysis. For most organizations, data is spread across many sources such as data warehouses, online databases and connected devices. It needs to be collected and “cleansed” to remove duplicate, missing, corrupt or inaccurate data, and then organized into a defined format for analysis.
- Divide data into two datasets: training data and test data. Training data is data that corresponds to known outcomes; it’s fed to the machine learning algorithm so it can be evaluated and can make predictions based on new data. The test data will be used to validate that the model can make accurate predictions.
- Run one or more algorithms against the dataset. Once the appropriate model type and algorithms are decided, the predictive model is built and deployed.
Predictive modeling is an iterative process. Once a learning model is built and deployed, its performance must be monitored and improved. That means it must be continuously refreshed with new data, trained, evaluated and otherwise managed to stay up-to-date.
Predictive Modeling Techniques
There are several common predictive modeling techniques that can be classified as either regression analysis or classification analysis. Regression analysis looks at a dependent variable (the action) and several independent variables (outcomes) and assesses the strength of the relationship between them. It can be used to forecast trends, predict the impact of a particular action or determine whether an action and its outcomes are correlated. Once you decide to use regression analysis, there are several types to choose from. Some of the most common include:
- Simple linear regression: The most basic form of regression analysis, linear regression establishes the relationship between two variables. To use a simple example, a store could use linear regression to determine the relationship between the number of salespeople it employs and how much revenue it generates.
- Multiple linear regression: Multiple linear regression can be used to establish the relationship between the dependent variable and each of the independent variables. A health researcher can use this technique to determine the impact of factors like smoking, diet and exercise on the development of heart disease, for example.
- Logistic regression: This type of regression analysis is used to determine the likelihood that a set of factors will result in an event happening or not happening. A bank trying to predict if an applicant will default or won’t default on a loan is a common use of logistic regression.
- Ridge regression: This technique is used to analyze multiple linear regression datasets that have a high degree of correlation between independent variables.
Classification analysis sorts data into categories for more accurate analysis. It uses a few different mathematical techniques, including
- Decision trees: This technique replicates the decision making process by starting with a single question or idea and exploring different courses of action and their possible effects through a “branching” process to arrive at a decision.
- Neural networks: Modeled on the human brain, this technique helps cluster and classify data to recognize patterns and identify trends that are too complex for other techniques. A retail site that recommends products based on a user’s past purchases is one example of neural networks in action.
Prescriptive vs Predictive Modeling: What's The Difference?
Prescriptive modeling is the practice of analyzing data to suggest a course of action in real time. Essentially, it relies on the insights produced by other analytics models to consider available resources, past and current performance, and potential outcomes to propose what action to take next. In an IT context, for example, prescriptive modeling can propose infrastructure improvements based on monitoring and maintenance data and even enable the system to make the necessary adjustments itself according to a pre-recorded script.
Prescriptive analytics is an extension of predictive analytics. While predictive analytics can tell you what, when and why a problem will likely happen, prescriptive analytics goes a step farther and offers specific actions you can take to solve that problem. Both types of analytics enable you to make better-informed decisions, but prescriptive analytics pulls the most value from your data, allowing you to optimize processes and systems for the short and long term. Read more about the differences between predictive analytics and prescriptive analytics.
Choosing the Right Predictive Model
There are several different types of predictive analytics models. Most are designed for specific applications, but some can be used in a variety of situations. They include:
- Forecast models: Perhaps the most common types of predictive analytics models, forecast models learn from historical data to estimate the values of new data. Forecast models can be used to determine how many calls a customer service agent can handle in a day, or how many copies of a bestseller a retailer should order for the coming sales period, for example.
- Classification models: These models use historical data to categorize information for query and response and provide broad analysis to help people take decisive action. Popular across a wide range of industries, they’re best used to answer yes/no questions such as, “Is this loan applicant likely to default?”
- Clustering models: This model sorts data together around common attributes. One popular application is customer segmentation, where the model can cluster a business’s customer data around shared attributes and behaviors. Clustering models use two types of clustering — hard and soft. In hard clustering, data points either belong to a category or they don’t. Soft clustering doesn’t put each data point in a separate cluster, but rather assigns a probability that a point belongs in every cluster.
- Outlier models: Outlier models identify and analyze abnormal entries within a dataset and are usually used where unrecognized anomalies can be costly to companies, such as in finance and retail. For example, an outlier model could identify a fraudulent transaction, assessing the amount, time, location, purchase history and the nature of the purchase.
- Time series models: This model uses time as the input parameter to predict trends over a specific period. For example, a call center could use this model to determine how many support calls it can expect in the coming month based on how many it received over the previous three months.
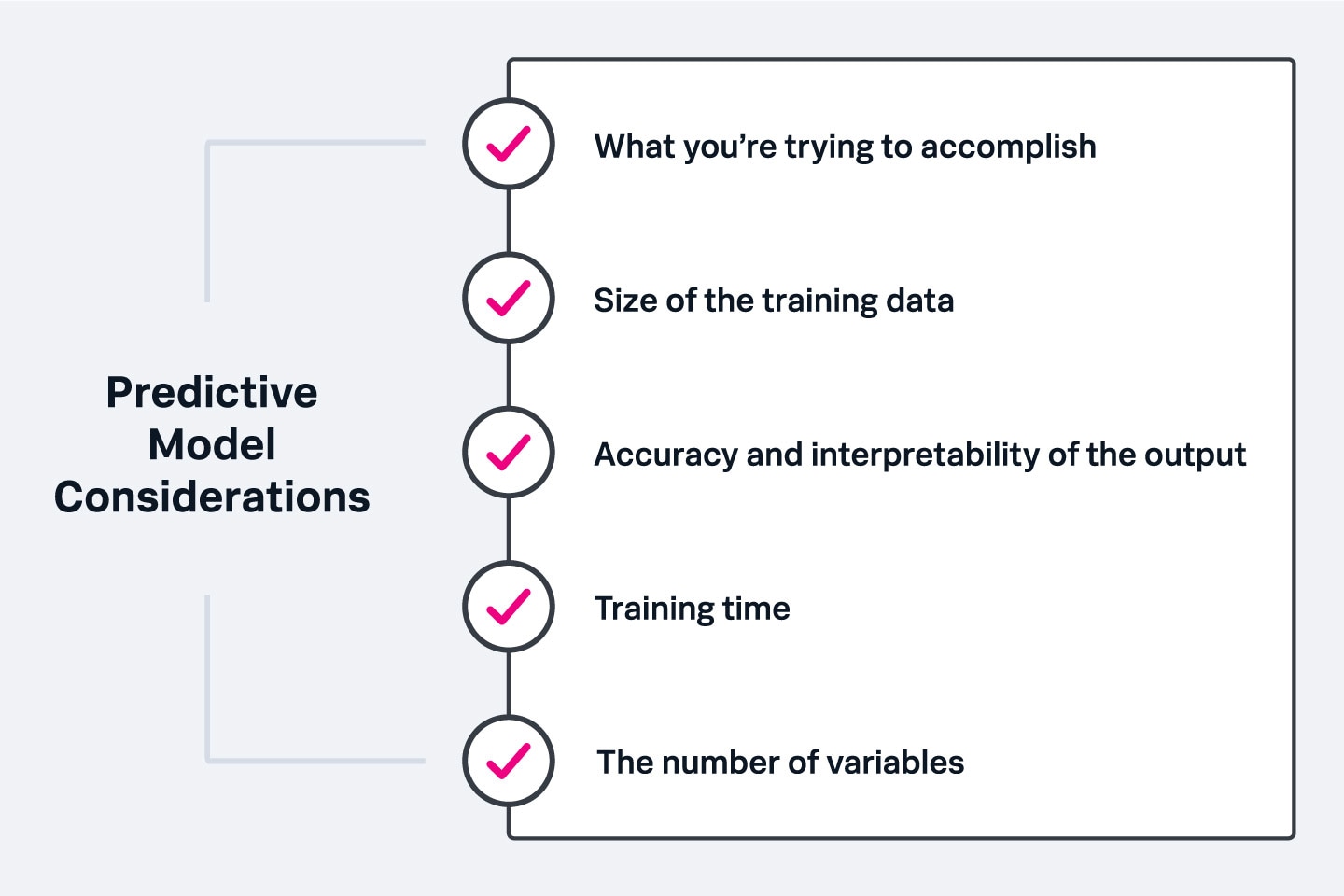
There are a few things to consider when choosing a predictive model:
- What you’re trying to accomplish: Forecast models are great for predicting future events based on past ones, while classification models are a good choice when you want to explore possible outcomes to help you make an important decision. The right model will depend largely on what you’re trying to learn from your data.
- Amount of training data: In general, the more training data you gather, the more reliable the predictions. Limited data or few occurrences of whatever you’re trying to measure within a dataset may dictate the use of different algorithms, versus a huge dataset with lots of variables.
- Accuracy and interpretability of the output: Accuracy refers to the reliability of the model's predictions, and interpretability is how easily they are understood. Ideally, your model will have a good balance of each.
- Training time: The more training data you have, the more time will be required to train the algorithm. Higher accuracy also requires a longer training time. These two factors may be the most significant in choosing a model for many organizations.
- Linearity of the data: Not all relationships are perfectly linear, and more complex data structures may narrow down your options to techniques like neural networks.
- The number of variables: Data with a lot of variables will slow some algorithms down and extend training time, which should be considered before choosing a model.
Ultimately, you will likely have to run several different algorithms and predictive models on your data and evaluate the results to make the best choice for your needs.
Examples of Business Benefits of Predictive Modeling
Predictive modeling is important because every business, regardless of industry, relies on data to make better business decisions. Predictive modeling enables you to have more confidence in a decision by showing you the most likely outcomes of whatever action you’re considering.
Some of the common business benefits can include:
- Improved Decision-making: By understanding probable future outcomes, businesses can make more informed decisions. Whether it's about allocating resources, setting up marketing campaigns, or selecting which leads to pursue, predictive insights provide guidance.
- Cost Savings: Predictive models can help businesses anticipate and manage risks, reduce waste, and optimize processes. For example, predicting machinery failures can lead to timely maintenance and avoid costly downtimes.
- Increased Revenue: By leveraging predictive analytics, companies can better understand customer behavior, segment their market, and target the most promising opportunities. For instance, predicting which customers are most likely to churn allows businesses to intervene proactively.
- Operational Efficiency: By predicting demand, businesses can better manage inventory, optimize supply chain processes, and ensure that they meet customer needs without holding excess stock.
- Enhanced Customer Experience: Predictive models can help businesses understand their customers' needs and preferences, leading to tailored product recommendations, personalized marketing messages, and more effective customer service interventions.
- Risk Management: Financial institutions use predictive modeling to evaluate loan risks, insurance claims, and potential fraudulent activities. By predicting which transactions are likely to be fraudulent, businesses can reduce their exposure to financial losses.
- Strategic Advantages: Gaining insights into future market conditions, competitive landscapes, and customer preferences enables businesses to position themselves more effectively and gain a competitive edge.
Challenges, Risksn and Assumptions
Mathematically performed predictions based on datasets are not infallible. Typically, problems with predictive modeling come down to a few factors. The first is a lack of good data. To make accurate predictions, you need a large dataset that is rich with the appropriate variables on which to base your predictions. That is not easy to come by for many organizations, as many organizations lack a robust data platform that can correlate all of an enterprise’s data, analyze information at a granular level and derive actionable insights from large datasets. Consequently, small or incomplete data samples can easily result in unreliable predictions.
Another obstacle to effective predictive modeling is the assumption that the future will continue to be like the past. Predictive models are built using historical data. But behaviors often change over time, which may render long-used models suddenly invalid. New and unique variables in different situations in turn elicit new corresponding behaviors and approaches that can’t always be anticipated with prior models. Thus, predictive models must constantly be refreshed with new data to keep pace with current behaviors in order to make accurate predictions based on them
Another common challenge with predictive modeling is model drift. Model drift refers to a model’s tendency to lose its predictive ability over time. It’s usually caused by statistical shifts in the data, and if left undetected, can negatively impact businesses by producing inaccurate predictions.
Should your business rely on predictive modeling?
Predictive modeling is sound data science, but it’s not omniscient. No predictive model could have forecasted the COVID-19 pandemic or how it would change consumer behavior on such a huge scale, for instance. Those once-in-a-lifetime circumstances aside, predictive modeling is a highly effective way to inform business decisions as long as you have the right solution and staff in place and are continually refreshing your model with new data.
Getting Started
To get started with predictive modeling, first decide what problems your organization would like to solve. Clarity about what you want to accomplish will yield an accurate, usable outcome, while taking an ad hoc approach will be far less effective.
Next, assess any skills and technology gaps in your company. While software solutions do much of the heavy lifting, predictive modeling requires expertise to be effective. Be sure you have the staff, tools and infrastructure you’ll need to identify and prepare the data you’ll use in your analysis.
Finally, conduct a pilot project. Ideally, this will be small in scope and not business-critical but will be important to the company. Identify your objective, decide what metrics you will use to achieve it and how you will quantify the value. Once you have your first success, you’ll have a foundation on which to build larger predictive modeling projects.
Wrapping Up
Predictive modeling is the ultimate tool in the analytics arsenal, allowing organizations of all sizes to make more confident, impactful decisions. With a systematic approach and the right software solution, you can start leveraging the power of predictive modeling to solve your most vexing business problems and uncover new opportunities.
What is Splunk?
This posting does not necessarily represent Splunk's position, strategies or opinion.