 By Stephen Watts March 31, 2022
By Stephen Watts March 31, 2022
No matter how much experience your team has managing logs in conventional application environments, you’re likely to face a steep learning curve when it comes to managing logs in Kubernetes.
That is because Kubernetes is a unique platform. K8s involves many more moving parts — and, by extension, logs — than conventional application environments. Which means that finding and analyzing those logs in a way that delivers actionable observability involves a level of complexity that far exceeds even the logging challenges associated with other types of distributed systems and computing environments.
You can master Kubernetes logging but doing so requires evolving your approach to logging. You must:
- Rethink the way you collect and analyze logs.
- Reconsider the role that logging plays in your overall observability strategy and culture.
To provide guidance along this path, this article will look at the fundamentals of Kubernetes logging. It explains why Kubernetes log collection is so challenging and why it’s hard to make sense of all the different types of logs produced by a Kubernetes environment. We’ll also explain how to avoid getting stuck in the mud of Kubernetes logs by simplifying Kubernetes log management without compromising the visibility that Kubernetes logs deliver into the complex, cloud-native environments it powers.

(For more on Kubernetes, explore our other expert articles: How To Set Up "Vanilla" K8s, Intro to Kubernetes Monitoring, Best Practices for Kubernetes Incident Response and The State of K8s Today.)
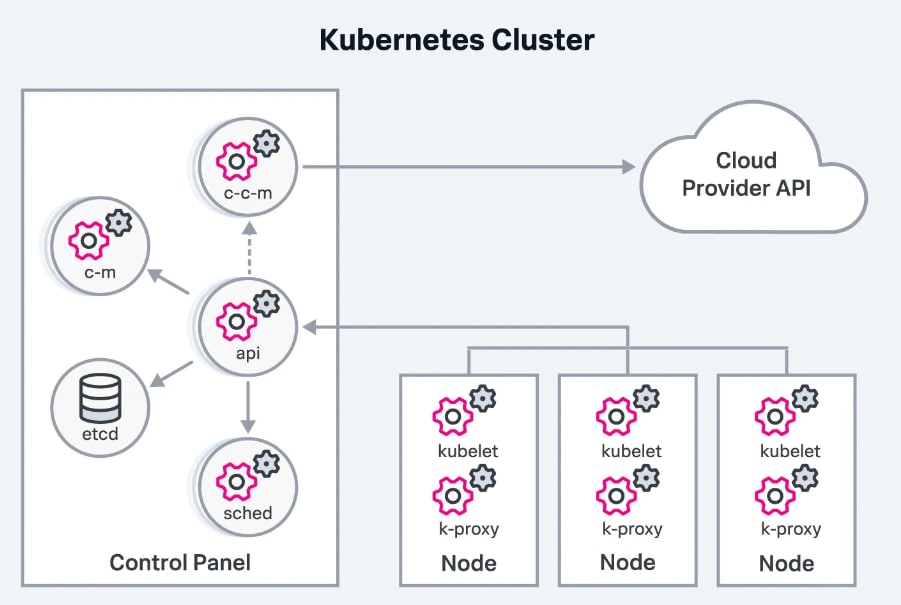
How Kubernetes logging works: The fundamentals
Although Kubernetes logs may not seem that different from other types of logs at first glance, they work differently in certain key respects.
Types of logs
First, there are two fundamentally different types of logs in Kubernetes:
- Containers and pods in which applications are deployed produce one type of log. These logs help you understand the performance and reliability of individual applications.
- Kubernetes itself produces the other log type, which provides visibility into the health of your overall cluster.
There are multiple types of logs in each of these categories. A single application is likely to produce multiple logs, one for each microservice instance that runs as part of the application. The cluster-level logs also fall into various categories: There are logs for:
- The primary node
- Worker nodes
- The Kubernetes API server
- Various other components of Kubernetes
Log locations
Given that there are multiple types of logs in Kubernetes, it’s not surprising that they are spread across a variety of locations. Some, like node logs stored in /var/log on the various servers that form a Kubernetes cluster, will be familiar to IT engineers. Others, like logs stored inside containers, can be more challenging to collect if you’re not accustomed to managing this type of log data.
Events and metrics
Although this article focuses on Kubernetes logs, it’s important to note that logs are only one of several sources of visibility in Kubernetes. Kubernetes also offers a metrics API, which is useful for collecting data about cluster health and resource consumption. It records certain types of events, too, such as the termination of pods.
This information is not fully available from Kubernetes logs, but you should collect and analyze this data alongside log data in order to gain end-to-end visibility into Kubernetes.
Challenges of Kubernetes logging
The logging architecture of Kubernetes itself, described above, is not especially complicated. Logging in Kubernetes becomes considerably challenging, however, due to the difficulty of actually collecting and analyzing the various logs inside your applications and cluster.
Lack of log centralization
One fundamental challenge is that Kubernetes logs are spread across a variety of different locations. You can’t tail a single log file or run a single command to pull all the log data from your cluster.
Instead, if you want to collect logs manually, you’ll need to toggle between a multitude of locations: all of your individual nodes, every single pod and more. Commands like journalctl can simplify this process to some extent, but they hardly make it easy.
Lack of built-in log management
Adding to the complexity of log collection is the fact that Kubernetes itself provides no native framework for managing logs. It simply produces the logs and leaves it up to IT teams to figure out how to manage them.
It does do things like delete log data from containers once their logs exceed 10 megabytes in size, but that doesn’t help as much as it hinders. It means you have to aggregate that data somewhere else before Kubernetes overwrites it if you want to ensure that it’s available for analysis.
(New to this topic? Start with our log management intro & our cloud log explainer.)
Diverse and evolving log formats
Logs from Kubernetes clusters and applications come in a variety of formats. In most clusters today, there is no standard log structure or approach.
Kubernetes developers have begun to address this problem by standardizing cluster-level logging via JSON formatting. However, this is a new feature that is available only in Kubernetes 1.19 and later. It also applies only to cluster logs; your application logs may still come in a variety of formats.
The bottom line here is that, although Kubernetes developers have made some efforts to make logs more consistent, the lack of common structure and formatting remains a challenge. And the mere fact that Kubernetes logging standards continue to evolve complicates the log management strategies that teams may develop. It’s difficult to know whether the logging approach you use on one version of Kubernetes will work equally well with a future release.
Lack of persistent log storage
Kubernetes does not offer persistent log storage by default for application logs. Instead, pods and containers write logs to their internal environments, which disappear permanently when the pods or containers shut down. This means that application log data must be aggregated to an external, persistent storage location in order to remain available for analysis. There are several approaches to doing this, such as:
- Using a so-called sidecar container to collect the logs.
- Streaming logs directly to an external location (instead of writing them to local storage inside your containers).
But these methods add complexity to your Kubernetes architecture and management workflows.
An alternate approach to Kubernetes logging
What all the above means is that Kubernetes logging is, in short, a pain — at least if you attempt to manage logs manually. Smart teams take a different approach.
Rather than trying to collect each and every log from across your pods and clusters, which is tremendously difficult to perform at scale, you can deploy a tool that automatically collects logs, no matter...
- Which format they are written in
- Where in your Kubernetes environment they’re stored
It’s just as important to leverage a log analytics solution that pairs your log data with other sources of Kubernetes visibility, such as metrics and traces, to deliver fully contextualized data about the state of your cluster and the applications running in it.
When you automate Kubernetes log collections and analysis, you avoid the pitfall of becoming hung up on the complexity of Kubernetes logs. You can focus on gaining actionable visibility from those logs...instead of struggling to figure out where each log is stored and how to collect it before it disappears. You can find this solution in Splunk Log Observer, which:
- Automatically collects logs of all types from all components of your Kubernetes environment.
- Eliminates the need for manual log aggregation.
Powered by Splunk Observability Cloud, Splunk Log Observer allows you to analyze Kubernetes log data alongside other crucial sources of Kubernetes visibility to ensure that you gain full observability.
With solutions like this, you can gain true observability into your K8s clusters without the headache of Kubernetes log management. Log Observer brings the power of Splunk logging to SREs, DevOps engineers and developers as an integral part of Splunk’s Observability Cloud. With a seamless and streamlined workflow for IT monitoring, troubleshooting and investigation, easily go from problem detection to resolution in minutes.
What is Splunk?
This posting is my own and does not necessarily represent Splunk's position, strategies or opinion. This article adapted from a post originally authored by Bill Emmett.