 By Stephen Watts October 25, 2023
By Stephen Watts October 25, 2023
Availability is the amount of time a device, service or other piece of IT infrastructure is usable — or if it’s available at all. Because availability, or system availability, identifies whether a system is operating normally and how effectively it can recover from a crash, attack or some other type of failure, availability is considered one of the most essential metrics in information technology management. It is a constant concern. After all, an entire business may not be able to operate if an essential piece of hardware or service is not available.
Any number of business processes and internal and external factors can impact availability, making it particularly difficult to achieve. Denial of service attacks, hardware and IT service failure and even natural disasters can all impact availability and extend the mean time to repair (MTTR). A problem on a third-party service provider’s shared cloud server can cascade downstream to impact another organization’s availability. And in any IT environment, numerous devices and services interact — and an issue with a single device or service can cause a wide-scale outage. For example, if a key database is corrupted, a critical web server may become unavailable, even if the underlying hardware, operating system and network have not been impacted.
Availability is commonly represented as a percentage point metric, calculated as:
Availability = (Total Service Time) – (Downtime) / (Total Service Time)
This metric can also be represented as a specific measure of time. For example, if Server X has a stated availability (or a promised availability) of 99.999% (known in the industry as ‘five nines’) over the previous month, it has a maximum downtime of 26 seconds per month.
In this article, we’ll examine how enterprises can achieve high levels of availability in a variety of operating environments, as well as the benefits and costs of doing so.
Understanding High Availability
High availability is achieved when a system has exceptional levels of availability — high levels of uptime, fault tolerance and resilience.
The definition of availability, or high availability, typically describes a service that almost never fails. Major websites like Google and Amazon — while not completely without downtime — are so reliable that they serve as high availability standards for other services. They rely on extensive, complex and very costly sets of technologies to ensure this level of availability. Utilities like power, gas and water are other common examples of high availability in action, as well as the components of an airplane’s flight systems and the equipment used in a hospital operating room.
High availability is also related to responsiveness. If a service is operational but is operating so slowly that it is frustrating end users, its availability may be called into question. While availability can be formally measured through the above formula that considers uptime as a binary data point — either the service is online or offline — when it is considered alongside related metrics like response time and error rate, a more nuanced evaluation of availability comes into focus.
The widely touted gold standard for true high availability is 99.999% availability, commonly referred to as “five nines.” As in the above example, 99.999% availability implies a downtime of 26 seconds per month, or about 5.5 minutes per year. If you consider the downtime involved in rebooting a personal computer after a power outage, you can see how demanding and difficult reaching five nines of availability can be.
How To Achieve High Availability
High availability is achieved by using technologies purposefully designed for the task. In computing systems, high availability is achieved through the following tactics and tools:
- Redundancy: Multiple systems run in parallel so if one fails, the other can immediately pick up the slack. Redundancy can occur locally and on a distributed basis; while local redundancy (multiple servers in a single room) are effective in the event of an isolated hardware failure, geographically distributed redundancy is useful in the event of natural disasters or other regional problems that may take out an entire data center. Large-scale service providers operate servers in dozens of regions spread across the globe to provide extreme levels of reliability.
- Scalability: Systems are designed to handle a sudden increase in workload (such as web traffic), either legitimate or malicious — as in the case of a distributed denial of service attack.
- Load balancing: These tools distribute workloads among servers/services to minimize the workload on any individual system and prevent any single service from becoming overloaded.
- Monitoring: IT staff can use intelligent systems to monitor the performance of all of the above in real time, giving them a heads up if problems begin to develop — preferably well in advance of an issue that could lead to downtime.
- Backup: Since high-quality backups ensure an efficient and timely recovery from an outage, they are an essential component of any high availability strategy.
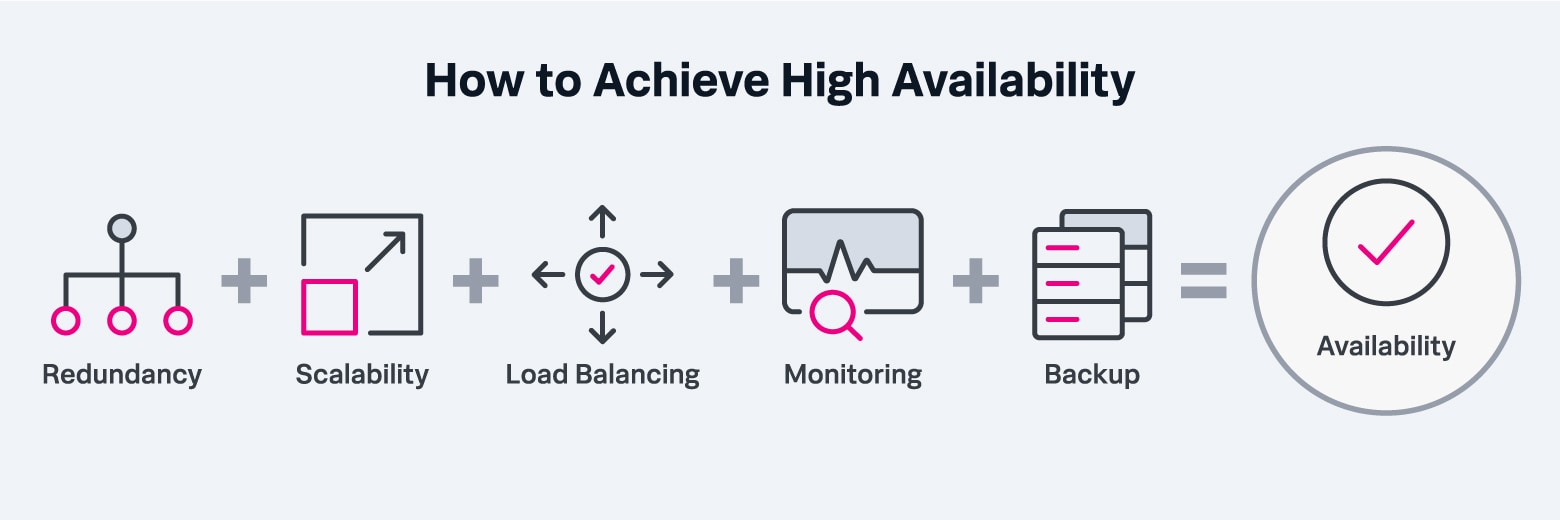
To achieve high availability you need a plethora of tools to ensure that all systems are running smoothly and optimally.
High Availability Compared with Fault Tolerance
High availability and fault tolerance are closely related topics, with one major distinction: While high availability systems have very low downtime, fault tolerant systems are designed to have zero downtime. Zero downtime is possible, at an extremely high cost and greater level of complexity. Fault tolerant systems are designed specifically to withstand faults — either in hardware components, software code or some other part of the infrastructure.
Fault tolerance is most commonly implemented in large-scale cloud environments. For example, Amazon AWS, Azure and Google Cloud all operate multiple availability zones — geographic regions in which data centers reside. By running operations simultaneously across several availability zones, an application can be designed to be fault tolerant. If a problem develops in one zone, multiple other zones will be able to pick up the slack. This design is similar to the way many highly available services are, but more complex. While a highly available design may strip down secondary copies of the application — for example, it may limit writability to the application when the primary instance of the server is offline — a fault tolerant system will not. In some cases, exact copies of the application will need to be run simultaneously in every availability zone, including accurate, real-time copies of any databases used. A user in a highly available system experiencing an outage may notice that it is slower or missing certain features. A user in a fault tolerant system will (in theory) never notice any change regardless of what has happened behind the scenes. That said, even the most well-designed system can’t be fully fault tolerant without a very high investment that even some of the biggest service providers often haven’t made.
The decision to implement high availability or fault tolerance often comes down to a question of cost and system criticality. Can you even get to 26 seconds a month? A more realistic target may only be three nines, or about 45 minutes a month. Is 26 seconds of downtime per month acceptable under any circumstance? Is avoiding that downtime worth a significant increase in your cloud services expenditures? There’s also the question of when the downtime occurs. If users are clustered in a particular geography, is the application considered down if it goes unnoticed? The answers to these questions depend on the application in question, and the enterprise’s specific level of risk.
High Availability in Cloud Computing
High availability is a commonly touted feature of cloud computing. Because resources are more fluid in the cloud, it is easier and less costly to design a system that is built with redundancy and load balancing features. In cloud operations, a design feature called clusters makes this possible. A cluster is essentially a group of virtual servers, each containing a copy of the production environment. Clusters are designed specifically to provide load balancing and failover features. If something happens that causes an application on one server to fail, the other servers in the cluster will instantly pick up the slack. In some high-workload environments, a cluster can have dozens or even hundreds of servers running in it.
Cloud systems also include many of the other items on the high availability checklist, including integrated load balancing features, seamless scalability when a service is under load, data backup systems and more — often provided as turnkey configurability options by the cloud provider. Specified availability levels are commonly built into cloud service providers’ Service Level Agreements (SLAs); if availability falls below that level specified by the SLA, the customer could be entitled to a refund or credit. However, it’s good to read the agreements carefully and understand how the definition of “down” is interpreted by the service provider.
High Availability in Architecture
In physical infrastructure and enterprise architecture, high availability is achieved through the use of redundant hardware and special software designed to provide load-balancing and failover features. Storage systems can be designed to be highly available through the use of mirrored drives and RAID arrays, which allow for storage to continue operating normally even if one hard drive fails. Power supplies and cooling systems can be made redundant so one waits to take over if the primary unit fails. Uninterruptible power supply (UPS) systems and generator units can provide backup power in the event of an electrical outage.
Much like the cloud example, clustering and load balancing can also be achieved in an on-premises environment — but at a substantially higher cost. In this case, multiple servers (also known as a cluster) run in parallel, each carrying a copy of the database, applications and other required software. Load balancing hardware (or software) directs incoming requests to the server in the cluster with the most availability, distributing those requests as evenly as possible. This ensures no single server becomes overloaded and that requests are handled with maximum speed. If a server becomes unavailable for any reason, the load balancer automatically takes that server out of rotation and distributes requests to the remaining devices until a repair is made.
High Availability in Networking
In networking, high availability relates to ensuring that network infrastructure remains operational and online. Network availability is crucial because it is the physical lifeline between the user and all resources, whether they are based on-premises or in the cloud. As with other types of availability, network availability is achieved by leveraging systems that allow for redundancy, load balancing and scalability.
Highly available network design revolves around using redundant networking hardware within the enterprise and often multiple ISPs. In a simplified example, two routers would be used to connect to two separate ISPs, allowing for four possible combinations of connectivity (Router A to ISP A, Router A to ISP B, Router B to ISP A, and Router B to ISP B). If one router fails — and if one ISP fails — network connectivity would be uninterrupted. This is a very basic example and high availability topology can get very complex as an enterprise scales upward in size — and as reliability demands increase. (For example, this example design can be imagined with two ISPs and four routers, four ISPs and eight routers, and so on.) Having a backup connectivity method is also something you may want to consider. Whether you have one or 10 ISPs, if the connections all go through a single conduit that’s vulnerable or subject to damage, you’re equally at risk.
Common Benefits of High Availability
High availability provides a number of benefits, including:
- Reduced risk: High availability reduces the risk of resources going offline at all, for any reason, which is critical for business continuity.
- Improved revenue: Reduced risk means improved revenue, as money-generating services are available to users more frequently.
- Quicker recovery: In the event that an outage does happen, high availability technologies minimize the time required to get systems up and running again.
- Better customer experience: High availability technologies balance loads so no single resource is overly taxed. This ensures all users receive roughly the same experience and no user waits an excessively long time for tasks to be fulfilled.
- Happier IT staff: High availability systems allow for a more relaxed recovery process when things go wrong, which means fewer fire drills and more satisfied staff.
- Better ability to scale: High availability solutions allow the enterprise to scale up more easily when additional resources are needed by adding additional servers to a cluster, either physical or virtual.
- Ability to meet SLA obligations: In some cases, high availability is mandatory because it is required by an SLA — established either with a customer or internally. Where service guarantees are in effect, the enterprise must embrace high availability.
Common Challenges in Achieving High Availability
Several roadblocks can make high availability difficult to achieve and challenging to maintain once it has been implemented. These include:
- High cost: High availability involves more hardware and software, plus additional technology (and higher pricing) to manage it all. We’ll discuss the cost implications of high availability in the following section.
- Lack of experienced staff: Service management of a high availability environment requires specific skills and certifications that may not be easy to come by. The worst time to find out your environment has not been properly configured is after a failure has taken place.
- Security concerns: A high availability environment is no more secure from attack than a standard availability environment. In fact, malware that is installed on one server in a cluster can easily propagate to other servers in the cluster. IT staff may be lulled into complacency by the reliability and load balancing features of high availability systems; the appropriate level of attention to cybersecurity must always be maintained.
- Maintaining data fidelity: One of the challenges of high availability is ensuring that data is accurately replicated among different data stores in real time; using outdated information in any process can lead to any number of errors, data corruption and worse. Managing a single source of truth for critical data is a major challenge in any high availability environment.
- Staff complacency: To optimize response times, IT service delivery teams need to conduct regular DR exercises to anticipate and troubleshoot potential pitfalls before they occur. If the infrastructure is fairly resilient so that potential problems and their resolutions are never discussed or explored, teams won’t be able to address issues as quickly when they do occur.
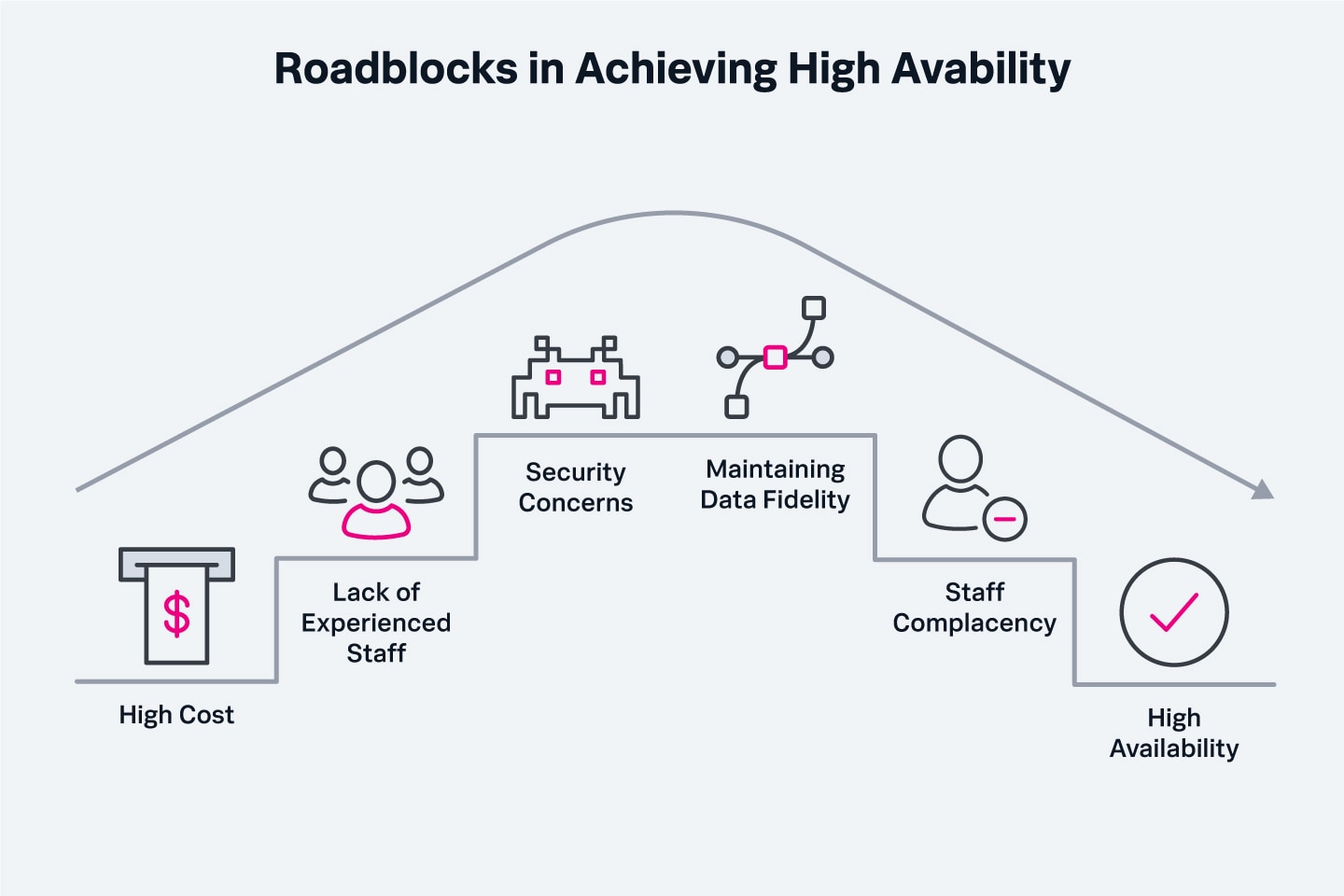
Barriers to high availability often include the human factor, such as lack of experienced personnel and complacency.
Cost Considerations for Maintaining High Availability
Achieving high availability can be costly. In addition to the direct cost of the product or service, high availability systems require more continuous maintenance and monitoring than traditional computing systems — all of which can have a significant business impact on your organization.
Is the financial outlay required worth the improvement in operational uptime? This is ultimately a risk-reward calculation. The enterprise must determine the total cost of downtime and compare that to the cost of eliminating it. If the cost of providing high availability services to limit downtime exceeds the cost of being offline (through lost sales, etc.), it may not be worth making the investment in high availability. In these cases, an enterprise may still be able to rationalize the expense of providing some level of high availability, but may instead choose to invest in a lower level — for example, four nines instead of five nines.
Availability Monitoring Overview
Availability monitoring is the practice of observing the status of essential technology systems, whether they are services based on-premises or in the cloud. At their simplest, availability monitoring tools can report on a system’s uptime status in real time by periodically polling a service on a set schedule to ensure it is responsive. Yet availability monitoring tools can also be used to create more complex tests to give more information and probe whether services are accessible from various locations around the globe, measure the speed of their response, report any errors and determine the reasons for failures. Availability monitoring works best when both real-time and predictive tools are used, enabling IT teams to react to issues quickly, before they become catastrophic.
Availability monitoring is a subset of availability management, an IT process designed to monitor and manage IT services — from planning and implementation through operations and reporting. Poor availability can have a massive impact on the enterprise, and in most organizations that includes a direct hit to revenue and profitability, unhappy customers and loss of reputation. Some of the best practices to ensure high availability include understanding the major sources of risk due to a potential outage in the enterprise, implementing a regular stress-testing plan and relying on automation wherever possible.
Availability Monitoring vs Availability Management
Availability monitoring is a practice nested within availability management, which is the process of planning, analyzing, operating and monitoring an IT service. The goal of availability management is to provide high availability and is a more comprehensive discipline than availability monitoring. The practice looks beyond simply monitoring the availability of a service and is designed to actively improve the availability of said service.
Availability management is closely related to a number of other fields in IT, including IT service management (ITSM), observability and application performance monitoring (APM). There are many monitoring solutions nested within APM, such as synthetic monitoring, server monitoring, cloud monitoring, network monitoring and real user monitoring (RUM). RUM takes availability monitoring a step further by providing visibility into the user experience of a website or app by passively collecting and analyzing timing, errors and dimensional information on end users in real time.
Availability management is also a component of the widely used ITIL framework, which sets out standard processes and best practices for optimizing IT services and minimizing the impact of service outages. As with availability monitoring, one aim of availability management is to ensure the enterprise is operating at the peak of its capabilities — though the ultimate goal of availability management is to promote continuous improvement.
The Importance of Availability Monitoring
Availability monitoring provides a method to ensure that technology products and services are in operation and running as expected. For almost every type of organization, technology is the lifeblood of operations. Take website performance monitoring, for example. If the home page of a business like Amazon or Facebook goes offline, a series of catastrophic events will quickly play out. Whether there’s an informative status page or simply an inability to connect, customers will immediately become angry, revenue will functionally drop to zero, and — eventually — users will begin to defect to alternatives, damaging the reputation of the business along with its financial health.
When Facebook experienced an outage in the fall of 2021 (along with sibling sites WhatsApp and Instagram), the sites were unreachable for around six hours. During this time, over 14 million users reported they couldn’t use any of Facebook’s apps or services. Experts estimated that each minute of downtime cost the company $163,565, totaling around $60 million in lost revenue that day.
There are also productivity costs associated with downtime, since a company will have to sound an “all hands on deck” alarm to the IT staff, forcing staffers to scramble into action in an attempt to make hasty repairs and get services back online.
The purpose of availability monitoring is to avoid this kind of catastrophic expense, ensuring critical technology services — not just website endpoints but any type of hardware or software – remain up and running and in accordance with expectations.
Another major function of availability monitoring is to monitor the performance of Service Level Agreements (SLAs) with third-party technology providers. When you engage in business with a service provider (such as an internet service provider or a cloud technology provider) the contract almost always specifies that the provider will reach a minimum level of availability, generally expressed as a percentage of uptime over a month or some other set time period. As such, it behooves the customer to keep track of the actual availability realized via uptime monitoring, for example. If the SLA is not being met — as measured by the customer’s availability monitoring solution — refunds or credits will be in order.
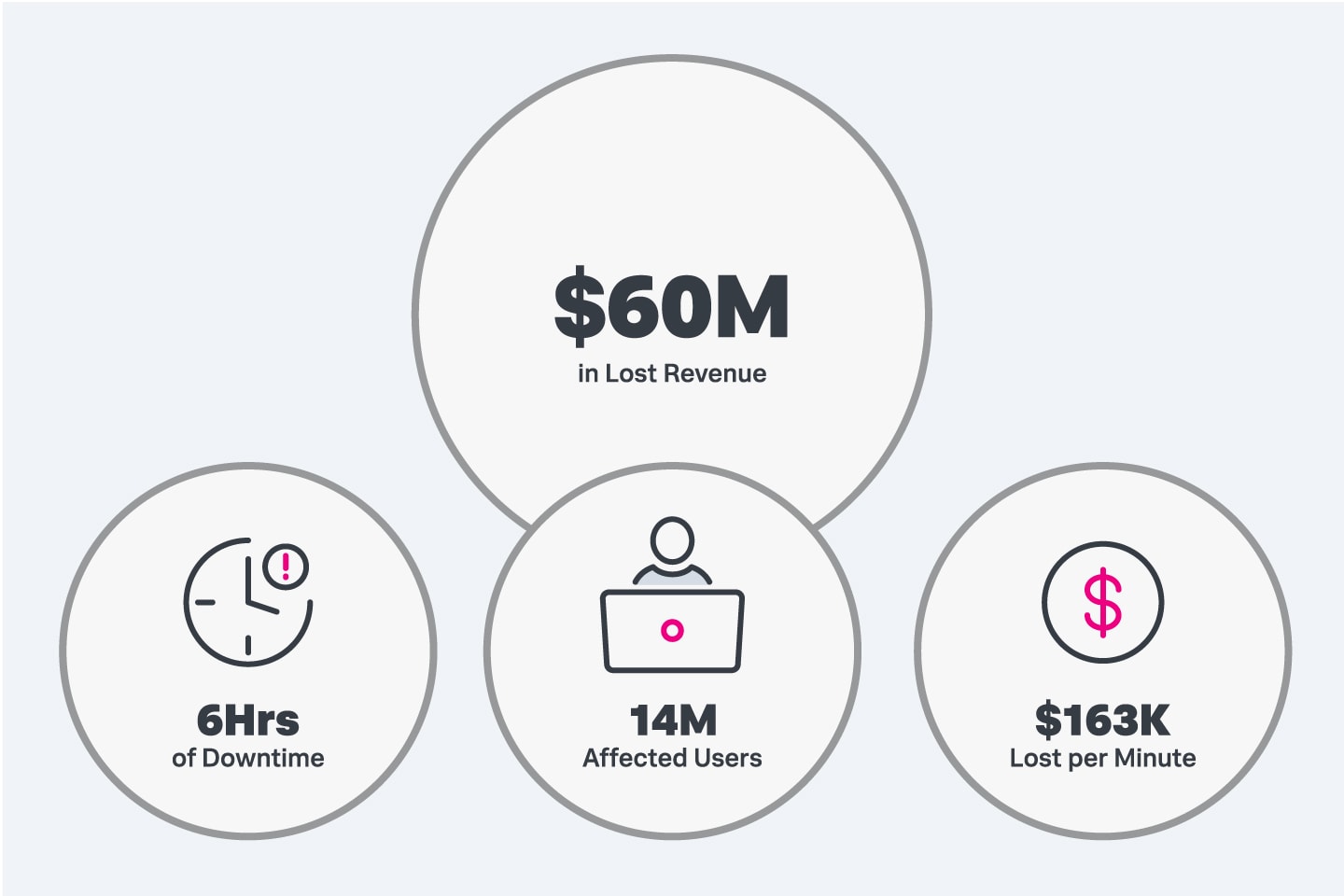
Downtime in an enterprise often results in customer attrition and significant financial losses.
The Bottom Line: Ensuring availability will remain critical for enterprises
Availability is one of the most essential elements of good IT management, even as enterprises have migrated from on-premises computing to the cloud. Availability is likely to become even more important as consumers increasingly rely on the internet and other network technologies in their daily lives. For all mission-critical services, every business needs to consider leveraging high availability tools and tactics in order to avoid disappointing customers and losing revenue.